
")

In 2024, linear regression continues to be a cornerstone technique in data science and predictive analytics. Its simplicity, interpretability, and effectiveness make it an essential tool for professionals seeking to model relationships between variables and make informed predictions. This article explores advanced techniques and best practices for mastering linear regression models, ensuring accurate and reliable predictions. We’ll cover key aspects such as feature selection, regularization, model evaluation, and the latest innovations in linear regression.
Understanding Linear Regression
Linear regression is a statistical method used to model the relationship between a dependent variable and one or more independent variables. The goal is to find the linear relationship that best predicts the dependent variable from the independent variables. The basic linear regression model can be expressed with the following equation:
Y=β0+β1X1+β2X2+⋯+βnXn+ϵY = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_n X_n + \epsilonY=β0+β1X1+β2X2+⋯+βnXn+ϵ
Where:
- YYY is the dependent variable.
- β0\beta_0β0 is the intercept.
- β1,β2,…,βn\beta_1, \beta_2, \ldots, \beta_nβ1,β2,…,βn are the coefficients of the independent variables X1,X2,…,XnX_1, X_2, \ldots, X_nX1,X2,…,Xn.
- ϵ\epsilonϵ represents the error term.
Advanced Techniques in Linear Regression
- Feature Selection and Engineering
Feature Selection: Selecting the most relevant features for your model is crucial for improving performance. Techniques such as Recursive Feature Elimination (RFE), Lasso Regression (L1 regularization), and feature importance from tree-based models can help identify the most significant predictors.
Feature Engineering: Creating new features or transforming existing ones can enhance the model’s predictive power. Polynomial features, interaction terms, and domain-specific features can capture complex relationships between variables.
- Regularization Techniques

Regularization helps prevent overfitting by adding a penalty to the model’s complexity. The two most common regularization techniques are:
Lasso Regression (L1 Regularization): Adds a penalty proportional to the absolute value of the coefficients. It can lead to sparse models where some coefficients are exactly zero, effectively performing feature selection.
Ridge Regression (L2 Regularization): Adds a penalty proportional to the square of the coefficients. Ridge regression helps in reducing the magnitude of coefficients, but it does not perform feature selection.
Elastic Net: Combines L1 and L2 regularization, balancing the benefits of both methods. It is particularly useful when dealing with highly correlated features.
- Model Evaluation Metrics
Evaluating the performance of linear regression models involves several metrics:
R-squared (R2R^2R2): Represents the proportion of variance in the dependent variable that is predictable from the independent variables. Higher R2R^2R2 values indicate better model fit.
Mean Absolute Error (MAE): Measures the average absolute difference between predicted and actual values. MAE is less sensitive to outliers compared to other metrics.
Mean Squared Error (MSE): Measures the average of the squares of the errors. MSE penalizes larger errors more than MAE.
Root Mean Squared Error (RMSE): The square root of MSE, providing an error metric in the same units as the dependent variable.
- Handling Multicollinearity
Multicollinearity occurs when independent variables are highly correlated, leading to unstable estimates of coefficients. Techniques to address multicollinearity include:
Variance Inflation Factor (VIF): Calculates how much the variance of an estimated regression coefficient increases due to collinearity. A VIF value above 10 suggests high multicollinearity.
Principal Component Analysis (PCA): Reduces the dimensionality of the dataset while retaining most of the variance, helping to mitigate multicollinearity.
- Interaction Terms and Non-Linearity
Incorporating interaction terms allows the model to capture how the effect of one predictor variable on the dependent variable changes with the level of another predictor variable. For example, an interaction term X1×X2X_1 \times X_2X1×X2 can be added to model the combined effect of X1X_1X1 and X2X_2X2.
Polynomial Regression: Extends linear regression by including polynomial terms of the predictors to model non-linear relationships. This technique can be useful when the relationship between variables is not purely linear.
Best Practices for Accurate Predictions
- Data Preprocessing
Ensure that the data is clean, with missing values appropriately handled and outliers addressed. Standardizing or normalizing features can also improve model performance, especially when using regularization techniques.
- Cross-Validation
Use cross-validation techniques to assess model performance and generalizability. k-fold cross-validation involves partitioning the data into k subsets, training the model on k-1 subsets, and validating on the remaining subset. This process is repeated k times, with each subset used as a validation set once.
- Hyperparameter Tuning
Fine-tune the hyperparameters of your linear regression model to optimize performance. Techniques such as Grid Search or Random Search can help find the best combination of hyperparameters.
- Model Diagnostics
Perform diagnostic checks to validate model assumptions, such as linearity, homoscedasticity (constant variance of errors), and normality of residuals. Residual plots and statistical tests can help identify potential issues.
- Updating Models
In a rapidly changing environment, continuously update and validate your models with new data. Regular model retraining ensures that the predictions remain accurate and relevant.
Latest Innovations in Linear Regression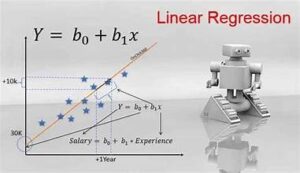
As data science evolves, new techniques and tools are enhancing the capabilities of linear regression:
- Automated Machine Learning (AutoML): Tools and frameworks like Auto-sklearn and Google AutoML automate the process of model selection, hyperparameter tuning, and feature engineering, making advanced linear regression more accessible.
- Explainable AI (XAI): Techniques like SHAP (Shapley Additive Explanations) and LIME (Local Interpretable Model-agnostic Explanations) provide insights into the contribution of each feature to the predictions, enhancing transparency and interpretability.
- Integration with Deep Learning: Combining linear regression with deep learning models, such as using linear layers in neural networks, allows for capturing complex relationships while maintaining interpretability.
Conclusion
Mastering linear regression models in 2024 requires a deep understanding of advanced techniques and best practices. By focusing on feature selection, regularization, model evaluation, and addressing challenges like multicollinearity, you can develop robust models that deliver accurate predictions. Embrace the latest innovations and continuously refine your approach to stay ahead in the dynamic field of data science.


{kind=link}